Lars Wirzenius: August, 2007
Contents
- August 15: Debian 14 years
- August 12: Floppy icons
- August 09: Free Thursday today
- August 08: Ode to my laptop, bzr uncommit
- August 07: Productivity fear
- August 01: Generating backup data sets
Wednesday, August 15, 2007
Debian: Debian 14 years
To celebrate Debian's 14th birthday, in Helsinki, Finland, on August 16, from 18:00 onwards, let's gather in AWK or Annankadun William K (the southern end of Annankatu) for a beer or two.
For those without calendars, that's tomorrow.
Sunday, August 12, 2007
Random thought: Floppy icons
This thought just struck me: the GNOME "save file" icon is still an image of a floppy (or it is at least in Gnumeric). How many people still remember what a floppy looks like?
Thursday, August 09, 2007
Random thought: Free Thursday today
Free Thursday today, at 18:00, at Teerenpeli in Kamppi.
Wednesday, August 08, 2007
Random thought: Ode to my laptop
I've been cleaning out my home directory from cruft, and
re-arranging things so that I can more easily find stuff in
the future, without resorting to grep -r. As a
result, I find old stuff I'd forgotten about long ago,
such as
Blinkenlites, which was not at all my own writing. Today's
amusement is all mine, from 2003 when I bought a new laptop.
Ode to my laptop
by Lars WirzeniusOh, my laptop, how I adore thee!
Wherever I am, so you will be!
If my co-workers I don't want to see,
I'll take you to the cafe with me!You're compact, and have every device,
nothing extra, but enough to suffice.
You're closed, I can't commit the vice
of adding hardware, even something nice!This makes my life rather easy,
hardware makes me queasy,
it's never logical, often greasy,
code is better, even when cheesy.Oh, my laptop, you are my friend!
My true and my trusted friend!
To your welfare I will tend,
my true and trusted friend!
Random thought: bzr uncommit
One of the things that occasionally happens to me is that I mistakenly commit too much. I use Bazaar (bzr) as my version control tool of choice, and tend to do "microcommits": every time I make a change that is a useful, if very small, step in its own right, and "make check" still passes, I commit, even if it is only a one line change.
This means that usually all the changed files need to be committed. Sometimes, but rarely, I make unrelated changes in several files at the same time, and then I need to commit each change separately. But then I forget to specify the files on the command line.
With CVS, I would just shrug and continue. With Bazaar, I do "bzr uncommit", which removes the latest commit from the branch, and then re-commit with the proper files.
This is a small, but important, change from CVS, for me. It makes me happy. "Ha! Foiled you again, you stupid over-eager Enter key."
I have no idea whether other modern version control tools have the same thing; this entry is not to advertize Bazaar, but share my joy in victory over Enter.
Tuesday, August 07, 2007
Random thought: Productivity fear
Every time I do a "Getting Things Done" weekly review, I am amazed at how easy it is, and also how much it energizes me. Yet every time it is time to start one, I fear it, and procrastinate, sometimes for several weeks.
Obviously I have a deep-set fear of being productive.
Wednesday, August 01, 2007
Obnam: Generating backup data sets
Sometimes in programming one gets to concentrate for a bit on a single, simple, pure program. A command line utility which is completely in batch mode, does not handle any kind of complicated data, does not need to deal with other programs, or the network, or anything nasty like that. Something where one can just look at the one or two interesting parts and not have to worry about anything else. This is the story of one such program.
I need a program to generate test data sets for backup performance testing. The program needs to be reasonably efficient, since the simulated backups may be rather large. My first attempt was not fast enough. There were two reasons for this: the way I was generating random binary data, and the way I was generating filenames.
The program generates random binary data to simulate large files, such as image, audio, or video files, and thus it needs to be uncompressible with the usual compression algorithms.
My first attempt was to generate each output byte with the Python pseudo-random number generator (random.randint). This only results in about 0.1 megabyte/s (on my laptop), so I needed to improve it. After some iteration and advice, I landed on the following: I generate random bytes with the Python PRNG (random.getrandbits), and feed these to an MD5 checksum. After each byte, I get the current digest and append it to the output. This way, for each random byte, I get 16 bytes of output. It isn't completely random, but it satisfies the uncompressibility requirement. This resulted in about 2.5 MB/s.
I then tweaked the code a bit, doing things like avoiding unnecessary arithmetic. I further decided to only feed the first few dozen bytes from the PRNG, and the rest as the same constant byte. The initial run of randomness is enough to make sure the output is unique for different files, so that compression doesn't find lots of duplicates of the big files. This resulted in a speed of about 6.6 MB/s on my laptop and about 13 MB/s on my server.
This still didn't make the program fast enough, but the remaining problem was not that writing the contents of one file was too slow, but operations on directories were very, very slow. After benchmarking with zero-byte files, turns out that at the slowest, with file counts in the millions, it would create only a few tens of files per second. That's empty files, so only requiring an update of indoes and the creation of a new directory entry. Obviously, the problem was that I was putting too many files in directories, causing the filesystem to spend a lot time scanning them.
I was creating up to 250 files per sub-directory, and then creating a new sub-directory. All of these sub-directories were going directly under the user's chosen output directory. To measure what the optimal size of a directory was, and whether to create two levels of sub-directories, I wrote a little benchmark program.
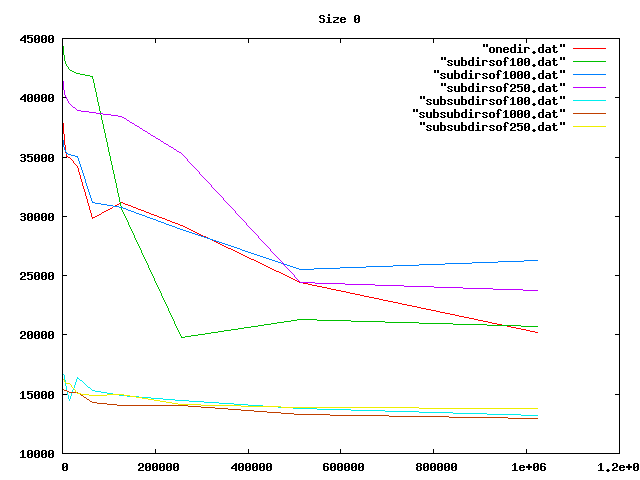
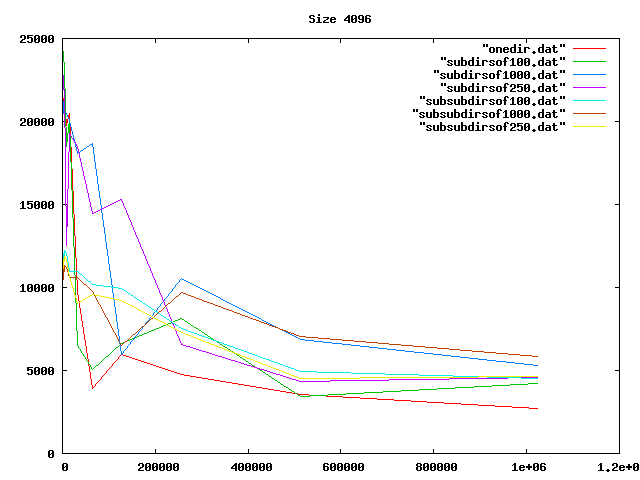
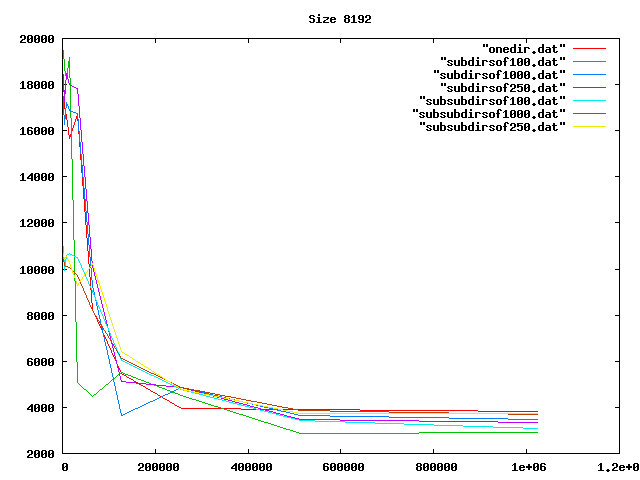
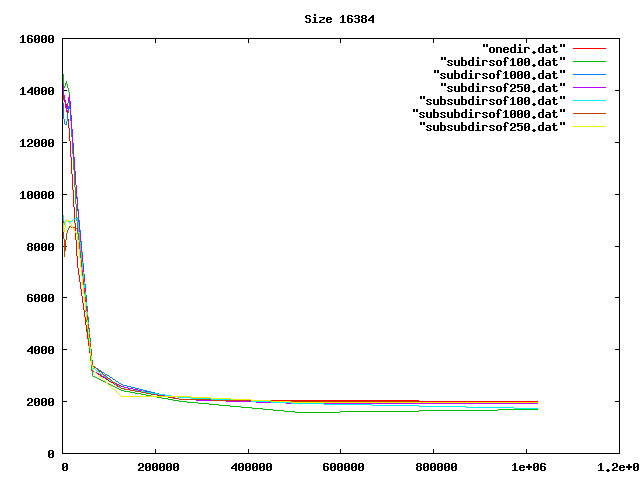
Some graphs from the benchamrks: for 0, 4, 8, and 16 KiB files, for up to one million files of each size. onedir puts all files in the same directory, subdirsofN puts N files per directory, and subsubdirsofN has two levels of directories, the leaf directories getting N files each.
From the graphs I deduced that overall, having two levels of directories and up to 1000 files per sub-directory was the best option of those tested.
On the other hand, the bigger the files, the less it mattered what the directory structure was. Perhaps the obvious reason for the slowness wasn't that, after all.
Then I realized my code was slow because I was doing an os.listdir (listing all files in a directory) for every directory every time I creted a file. Fixing that idiocy made the code so fast that any overhead from the directory operations was no longer relevant. But at least I had some nice graphs.
On the server I will be generating my test data the program is now happily generating just over 11 MB/s of test data. I wouldn't mind having it be a lot faster, but it's fast enough. It will take hours to generate hundreds of gigabytes, but I hopefully won't need to do that very often. Thus, further optimization isn't worth my time, right now.
The program is genbackupdata, in case anyone else cares about it.