Lars Wirzenius: Random hacks, 2004
Contents
- December 31: Sound Converter 0.5
- December 27: Sound Converter 0.4
- December 15: Sound converter dilemma
- December 06: Sound Converter 0.3
- December 05: No Sound Converter version 0.3
- November 28: Sound Converter 0.2
- October 29: Sound converter application, version 0.1
- October 23: Sound converter application
- October 20: Sound converter doodling
- September 05: isutf8 utility
- August 06: McKenzie's dnd-list
- May 02: Procedure for ripping CDs
- April 25: Of what use is Dijkstra?, Simple scripts
- April 10: Language benchmarking, 0.1
- April 05: md5sum.py updated
- April 04: Language implementation speed benchmark
- March 29: md5sum.py
- March 26: My sex.py is getting bigger
- March 21: rss2email considered useful
- March 18: sex.py: plugins or not?
- March 14: sex.py
- March 12: fmt.py
- February 22: Atom feed, RSS hopefully fixed
- February 19: RSS1, not RSS2
- February 17: IE and Opera don't like ', comments@liw.iki.fi re-enabled, figlet saves the day
- February 13: I'm still stupid
- February 01: URLs in my RSS should work now
- January 29: Generating Finnish SSNs
- January 20: RSS
- January 19: Log re-engineering
Friday, December 31, 2004
Random hacks: Sound Converter 0.5
Finland has started its traditional war on the new year. Teenagers and drunk men all over the country are playing with explosives in homes, backyards, on streets, in crowds, and anywhere else they fancy. It is therefore good to listen to some music to drown the explosions. But wait! All the music is in the wrong format. Darn.
Sound Converter to the rescue! With the help of
decodebin, Sound Converter can now read any
sound file formats that GStreamer supports. The new version
0.5 also touts a manual page. Read it before it becomes
obsolete!
See my programs page for the download link. One of these days I should probably make a page for Sound Converter, with screenshots and stuff, but not yet. I also didn't have time to make a Debian package yet, but there is always next year.
Monday, December 27, 2004
Random hacks: Sound Converter 0.4
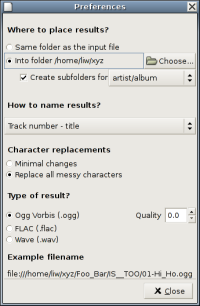
Sound Converter preferences window
I have just created version 0.4 of my sound converter application. I've fixed various bugs and made it possible to configure where output files are placed and how they are named. Also included is support for drag-and-drop: you can drag sound files from Nautilus to the list of input files. Also, three formats are now supported for input and output: WAV, FLAC, and Ogg Vorbis. I tried, but failed, to add support for MP3 as well. I'll look at that closer for the next release. I'll also make a Debian package for the next release, I think.
I hope that this version should now be generally useful, so I would appreciate any and all feedback. Thanks. The source code is available from my programs page.
Wednesday, December 15, 2004
Random hacks: Sound converter dilemma
I have dilemma with my sound converter application: where should output files be put and what should I do if they exist already? For extra kicks, what should I do if the output file is the same as the input file?
At the moment, I put the output file in the same directory
as the input file, and change the suffix to create the output
file. So, if the input file is /foo/bar/sound.flac
the output file will be /foo/bar/sound.ogg
(assuming conversion is to Ogg Vorbis). This is simple, but
has some problems. For example, one use case scenario
is when the input files are on a CD or DVD, and the output
should go to the hard disk. So the user should be able to
specify the output directory in some cases.
Another use case scenario is that the user wants to store the output files on the hard disk in a directory tree. Should I make my application be able to create subdirectories based on meta data tags (one directory for each artist, one below that for each record, for example)? Sound Juicer does this, so perhaps I could copy what it does.
Suppose the user wants the output files go to the same directories as the input files. If the input is a high quality Ogg Vorbis file and the output file should also be a low quality Ogg Vorbis file, what should I do? Abort with an error message? Add ".new" somewhere in the filename? Use a temporary filename and then replace the input file with that? Send the output to the user via e-mail?
Life is so much easier for command line programming, where aborting with an error message is always the right thing to do at the first sign of trouble.
Something good has happened, however. Chris Jones sent
me a patch to make my application accept dropped files from
Nautilus and Rhythmbox. I re-wrote the patch, but anyway,
it seems to work. This is nice. I also note that the overhead
of Python and GStreamer seems to be fairly small as compared
to using oggenc from the command line.
Monday, December 06, 2004
Random hacks: Sound Converter 0.3
I decided to release version 0.3 of my sound converter after all. The 0.2 version seems to have same problem, so 0.3 is not a regression. So, Sound Converter 0.3 is released.
Sunday, December 05, 2004
Random hacks: No Sound Converter version 0.3
I meant to make a new release of my sound converter application, now that it uses GNOME-vfs for I/O and has a command line interface as well, but during pre-release testing, I found out that in GUI mode it tends to crash. It seems that my previous release also has started to crash. Both crash by segfaulting the Python interpreter, no less. Either I've found a bug that exists in both versions of my application, or the GStreamer stuff has some bug. Or something. So I won't be making a release tonight. I'll have to figure out what the problem is and I'm feeling like doing that tonight. This smells like a race condition, and I hate debugging those.
Sunday, November 28, 2004
Random hacks: Sound Converter 0.2
I've hacked a bit on my sound converter application for the GNOME environment. Now releasing version 0.2. It is still very raw, but it works again, after I broke it and when things changed in the Python GStreamer bindings.
I still only support Ogg Vorbis output, but the input can also be Ogg Vorbis. I intend to add support for more formats (input and output), just haven't had the time to do it yet.
The app should now be usable by people who know how to make backups.
See my program page for the source. No Debian package yet, it's too raw for me to bother with it yet.
Friday, October 29, 2004
Random hacks: Sound converter application, version 0.1
Hacked a bit on my sound converter application again and made version 0.1. This release includes a Makefile (for installation), and a preferences dialog that lets you set the quality level of the Ogg Vorbis output. It also won't blindly overwrite files that already exist.
I think this version should be good enough to use (I've installed in my /usr/local/bin) if what you need is to convert FLAC to Ogg Vorbis. I'll have to figure out reasonable ways to support more input file formats. Preferably I would like to support everything that the GStreamer installation on the machine supports.
Saturday, October 23, 2004
Random hacks: Sound converter application
My little sound converter application has progressed a bit today. I got unofficial Debian packages of the GStreamer Python bindings from Joe Wreschnig and read about using GStreamer for a couple of hours. After that, both reading tags from FLAC files and converting FLAC to Ogg Vorbis was easy. GStreamer rocks.
It now actually does something useful. Now that I know how to do all the technically difficult stuff (the actual conversion), I should probably start thinking about usability. The code is only 430 lines of code, so rewriting everything from scratch to improve usability won't be much of a problem.
In case anyone is curious, I put up a tarball. Note that this is dangerous software, it may well remove all your files.
Wednesday, October 20, 2004
Random hacks: Sound converter doodling
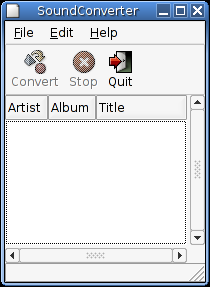
I spent much of today re-learning GTK+ stuff and wrote the beginning of a small application for converting sound files to other formats.
The application doesn't do much yet, it merely lets you add and remove files to the list. I'm under the impression that GStreamer is the current best choice for reading meta data from the files and for doing the actual conversion, but the Python bindings for it haven't been made part of Debian yet. I hope that the preliminary packages I've been told about will work well enough that I can finish off this little application. It would be nicer to have a nifty GUI tool than doing things on the command line every time I rip a new CD. (I rip to FLAC and the convert to Ogg Vorbis.)
Sunday, September 05, 2004
Random hacks: isutf8 utility
Since I'm moving to using UTF-8, I will need to convert all my files to use UTF-8. To do this, I will need to find the files that are not yet UTF-8. Last night (well, morning actually, just before I went to bed) I couldn't find a tool for telling me whether a file is UTF-8 and if not, where the first problem byte is. So I wrote one. See isutf8 on my programs page. Not tested much, just a quick hack.
Friday, August 06, 2004
Random hacks: McKenzie's dnd-list
Callum McKenzie wrote dnd-list, a small tool for displaying the drag and drop types provided by an application. I have had a need for this earlier, and will have again once I start working on Lodju again. To make it a tad nicer for my use, I added a "Clear" button and made the window size a bit larger and sent the patch to McKenzie.
Sunday, May 02, 2004
Random hacks: Procedure for ripping CDs
As I mentioned earlier, I managed to delete all my Ogg Vorbis files and I didn't have any backup of them. I'm now in the progress of ripping my entire CD collection again. Luckily, this is now easier and more comfortable than before. The procedure I settled on is this:
- Rip each CD with Sound Juicer into FLAC.
- When there are enough FLAC files to fill a DVD+R, burn one.
- Convert burned FLAC files to Ogg Vorbis using oggenc -q0.
Sound Juicer is a very nice GNOME program for ripping CDs. It requires the minimum of fuss, either in configuring it or while running. Everything is as automatic as it pretty much can be. I recommend it very warmly.
I burn the FLAC files on DVD so that I don't ever have to rip my CDs again. Ripping is tedious and slow. If I didn't force my CD drive to be slower than its ridiculously high maximum, ripping would also be quite noisy. FLAC is a good format for archiving, since it is lossless: I can go back to the FLAC files and re-encode them in various formats without losing any quality due to multiple lossy encodings.
I am lucky enough to be quite insensitive to loss of quality and I can therefore use quality level -1 without noticing any difference between that and a FLAC file (but I still encode using quality level 0). I've now ripped about 24 hours of music and they use less than 650 megabytes of space. This means I can live with a smaller laptop hard disk than I would otherwise.
Sunday, April 25, 2004
Random hacks: Of what use is Dijkstra?
The other night I was having trouble sleeping. To make work related thoughts go away I spent a while writing a command line tool that implements Dijkstra's shortest path algorithm. It reads in a text file giving node names and their distances and prints out the shortest path between two nodes given on the command line.
I haven't actually found any use for it yet. The most obvious one would be to optimize travel, but getting reliable data for that is expensive and, anyway, there is a "pathfinder" service for the greater Helsinki area on the web already.
Random hacks: Simple scripts
Joey Hess wrote in his log about a simple script he wrote to select songs and play them. He prefers it over the song selector in XMMS, which is hardly surprising, since the XMMS selector is quite primitive. (In fact, it is the primary reason I prefer Rhythmbox.)
Inspired by this, I'll mention a script I wrote a couple
of years ago: ~/bin/movies. I have a web page that
lists all the movies I have, partly to make it easer for friends
to borrow them and partly to make it easier for me to avoid
buying duplicates. I also record when I've watched a movie
and I wrote the script to randomly pick a movie to watch next.
It can choose randomly from all or those I haven't watched in
a year, or it can list all the ones I haven't yet seen at all.
I find the script useful, since otherwise I spend an hour in front of my movie collection agonizing over which one to choose. I am the donkey between haystacks.
Saturday, April 10, 2004
Random hacks: Language benchmarking, 0.1
I've received some responses to my log entry about a speed benchmark for language implementations. Most importantly, kind people have sent implementations in Ruby (Dafydd Harries), Tcl (Esko Arajärvi), Haskell (Isaac Jones), and O'Caml (Mike Furr), and I've also written an implementation in AWK myself. Unfortunately, the Tcl and Haskell versions require too much memory (stack or heap) and I can't run them with the huge input file I use with the others. Until they can be fixed, I'll post the current results with the other implementations.
| version | simple | longline | huge | binary |
|---|---|---|---|---|
| daf.rb.ruby1.8 | 0.2 / 0.0 | 0.5 / 0.0 | 323.2 / 34.3 | 0.0 / 0.0 |
| liw.awk.gawk | 0.1 / 0.0 | 0.1 / 0.0 | 97.3 / 0.9 | 0.0 / 0.0 |
| liw.awk.mawk | 0.0 / 0.0 | 0.4 / 0.0 | 42.5 / 0.7 | 0.0 / 0.0 |
| liw.gcc-2.95 | 0.0 / 0.0 | 0.5 / 0.0 | 54.4 / 0.6 | 0.0 / 0.0 |
| liw.gcc-3.2 | 0.0 / 0.0 | 0.5 / 0.0 | 54.8 / 0.7 | 0.0 / 0.0 |
| liw.gcc-3.3 | 0.0 / 0.0 | 0.5 / 0.0 | 54.0 / 0.6 | 0.0 / 0.0 |
| liw.py.python2.3 | 0.1 / 0.0 | 0.2 / 0.0 | 98.9 / 0.6 | 0.1 / 0.0 |
| mfurr.ocaml | 0.0 / 0.0 | 0.2 / 0.0 | 36.6 / 0.7 | 0.0 / 0.0 |
The first column gives the benchmark implementation and the four remaining columns are the four different inputs I give to the programs. "simple" is a single copy of the GPL, version 2. "longline" is a single long word, one million characters. "huge" is 5000 copies of the GPL v2. "binary" contains some binary characters as well as 100 instances of the same word. For speed comparisons, the "huge" input is the interesting one, the others are really there only to make sure the programs handle different kinds of inputs correctly.
The times in the four input columns are user and system time. Each combination of program and input is run and timed five times and the median of each time is used.
With the small inputs, there are a few interesting things to note. First, with the "binary" input, which is only 800 bytes in total, pretty much only measures startup speed. It would seem that Python has a slight disadvantage here. More interesting are the large variations in speed with the "longline" input. GNU awk does remarkably well, while Mawk, another AWK implementation, does much worse: indeed, almost as badly as my own C code. Python and O'Caml do almost as well as GNU awk.
With the interesting input, "huge", the real speed differences become visible. First, note that all system times are very small: most of the processing happens inside the user code. This is good, because it means that the benchmark measures the language and benchmark task implementations and not Linux kernel code. For some reason the Ruby code does use quite a lot of system time as well. I did not investigate why, at least not yet.
The fastest program was the O'Caml one. My C programs were quite a bit slower, even Mawk was faster than my C code. Either this means that my implementation is crock or these two language implementations really are quite good. AWK has a reputation of being quite slow, but this task is pretty much exactly suited for it. Python and GNU awk did fairly well. Ruby was quite slow.
It is too early to draw any conclusions about the actual speed differences of the language implementations in question. The programs can and hopefully will be improved. The Ruby program, in particular, was written to be simple, not to be fast. I don't know Ruby myself, but perhaps someone who does would like to contribute a faster version?
If you use these timings to claim that a particular language implementation is faster or slower than another, I will come and be cross at you.
Note that now that I reserve the right to change the inputs. Don't count on the input being GPL v2 in the future, that would make things too easy to optimize.
See lang-bench-0.1.tar.gz for details, if you are interested.
Monday, April 05, 2004
Random hacks: md5sum.py updated
I updated my md5sum.py script. It now has --help and --quiet options, and ignores a leading asterisk in a filename, which some md5sum programs seem to add to indicate a binary file.
Probably very few people like this, but I find it useful, and so does a friend of mine, so it isn't a complete waste.
Sunday, April 04, 2004
Random hacks: Language implementation speed benchmark
In my search for a new favorite programming language, one of the factors I favor is execution speed of programs. It is hardly the only factor, but one that happens to be measurable. I'm slowly setting up a benchmark suite to measure things that matter to me. The first benchmark counts frequencies of words:
Read text from the standard input and count the number of times each word occurs. Convert letters to lower case. Order the words according to frequency, words with the same frequency should be ordered in ascending lexicographic order according to character code. Print out the top N words, where N is a decimal number given on the command line. Each output line must contain the count, a space, and the word (in lower case), and end in an ASCII LINE FEED character. Output must contain exactly N such output lines and no other output lines.
A word contains only ASCII letters A through Z and a through z (convert upper case to lower case) and ASCII digits 0 through 9 and is not empty. All other characters separate words and are ignored except to notice word boundaries. Word boundaries only occur at the beginning and end of the file and at non-word characters. You may not assume a maximum length for the word, line, or input file.
For more information, see the README or download the tarball.
I have implementations in three languages so far: C, Python, and "shell" (using tr, sort, uniq, and tail). I've ran them with three versions of gcc and two versions of Python.
| user time | system time | |
|---|---|---|
| gcc 2.95 | 54.8 | 0.8 |
| gcc 3.2 | 55.3 | 0.8 |
| gcc 3.3 | 54.4 | 0.9 |
| Python 2.2 | 106.8 | 0.4 |
| Python 2.3 | 103.6 | 1.6 |
| shell | 639.6 | 6.6 |
These numbers are just a teaser. They only show run times for a particular large input file. The programs have not gone through extensive optimization and can probably be improved a lot. I haven't even started experimenting with gcc options. I'm also missing all the languages I'm really interested in, since I haven't yet had time to learn them in order to write implementations of this benchmark.
Monday, March 29, 2004
Random hacks: md5sum.py
I have at least two versions of the md5sum
command on my system. One from textutils, the other from dpkg.
They seem to be slightly different, but mostly compatible.
Neither is, however, very nice to use interactively: I get
very annoyed while creating an md5sum.txt at
the root of a CD or DVD, or while checking them. It would
be nice to get some progress information.
There are some other annoyances. When creating a checksum file, it is easy and natural to try to do it like this:
find . -type f -print0 | xargs -0 md5sum > md5sum.txt
Note how carefully I have used -print0 to avoid
having problems with filenames containing whitespace. The problem
with the above command line is that it creates md5sum.txt
before it starts executing the commands. This means that
md5sum.txt will contain itself, which will cause
trouble.
An aesthetic problem is that all filenames will begin with
./ even though there is no benefit to that.
A minor issue while checking is that as md5sum.txt
filenames relative to the root of the CD or DVD, one has to
change the current working directory there. This is an
unnecessary.
I finally got enough of these minor annoyances, and wrote
my own program for creating and checking MD5 checksums:
md5sum.py.
Perhaps someone else will find it useful as well.
ObNIH: I had to write my own program from scratch, rather than modify the textutils one, because the dpkg or textutils one is in C and the kinds of stuff I wanted to do is too tedious for me to be bothered to write them in C. The actual MD5 computation is provided by the Python standard library, the stuff I wrote is just dressing on top of that.
Friday, March 26, 2004
Random hacks: My sex.py is getting bigger
sex.py the program is now 1539 lines in four files. This is getting seriously big. On the other hand, it is also getting more usable. At least I think so. Probably very few other people are going to be particularly interested in this (but in case you are, check the tarball).
Sunday, March 21, 2004
Random hacks: rss2email considered useful
Joey Hess mentioned in his web log that he prefers to
read logs and news web sites (well, the RSS feeds of both)
using rss2email. I thought this sounded like
a nice idea and have been testing it for a couple of weeks
now. Now I think it is a great idea.
The most important benefit of rss2email
for me has been that it has all but eliminated the
neurotic clicking on reload to see if
Planet Debian
or various other web sites have been updated.
I don't have a neurotic need to read e-mail all the
time. Most of the time e-mail is either spam or bad news
or someone wanting me to do something. I read e-mail
only when I don't feel like doing something else. This
combined with rss2email takes off much
of the pressure of keeping up with other people's web
logs. I get them by e-mail, and can read them whenever.
Even off-line.
Thursday, March 18, 2004
Random hacks: sex.py: plugins or not?
I just realized today on the bus home that it should be simple to add plugins to sex.py, my new fledgling editor. Many successful programs have plugins and I wonder if they are a good idea. I have traditionally personally strongly preferred programs that have exactly the correct functionality designed into them with the best possible taste. I might experiment with plugins for sex.py and see if it attracts other people.
(I wonder how many content filters will start censoring my log now.)
Sunday, March 14, 2004
Random hacks: sex.py
On Christmas day I played around with the GtkTextView widget in GTK+. It is quite awesome in its handling of Unicode and fonts and stuff. It is almost everything you want in an editor. More specifically, it is almost everything I want in an editor. After failing to find a satisfactory Unicode capable editor for a GNOME desktop (see earlier log entry), I figured yesterday I might as well see how hard it would be to turn GtkTextVew into a real editor.
I started with the three hundred lines of Python and a fairly simple Glade file I made on Christmas day. After two days of hacking, I have added a thousand lines of code, and now this thing is fairly usable. Yes, I'm now writing this log with the new editor. Have only added three bugs to the to do list while writing this entry.
Incidentally, 330 of the thousand lines I added today were the fmt.py program I wrote the other day. The new SeX has builtin paragraph formatting!
Friday, March 12, 2004
Random hacks: fmt.py
I had trouble sleeping last night and was too pissed off to work on work stuff. Instead I decided to solve a problem I've had for several years: in my editor, I use fmt(1) to format paragraphs (vi users are probably with me on this, Emacs users have it built in). fmt is not terribly intelligent, even in the GNU version, in dealing with, say, text that has been quoted for e-mail or when every line begins with a programming language comment marker. GNU fmt has command line arguments for dealing with these, but they have to be adjusted for each paragraph, and that is tedious. The par program is in many ways more powerful than fmt, but it also requires more work for each invocation. Either that or it requires spending lots of magic on coming up with a working configuration and I'd rather spend the magic on writing my own stuff. (NIH, here we come again.)
The result of a few hours of tired, pissed-off hacking, fmt.py, can be downloaded from my programs page. I've started to use it myself, but it probably needs some attention before it is generally useful.
The line breaking algorithm is very stupid at the moment. If the program works well otherwise, I might want to have a look at the TeX stuff for this.
(Why not patch fmt? fmt.py is 330 lines of Python; I would not want to do the string manipulation in C. I hate doing string manipulation in C. See! I'm being totally rational about having to rewrite everything myself.)
Sunday, February 22, 2004
Random hacks: Atom feed, RSS hopefully fixed
My log now has an Atom feed as well. It might be as broken as my RSS feed, but hopefully I fixed that as well, at least as far as Planet Debian is concerned. My XML element attributes were delimited by apotrophes ('), which is valid, but the Planet code seems to not like them, so now I use quotation marks (") instead. Let's try a link: debian. Earlier, this wouldn't work.
It seems I also need to use absolute URLs (at least for images), but I can live with that, at least for now.
My RSS file is again version 2. To avoid the earlier mishap of lots of old entries becoming new ones, my RSS file now only contains the latest entry. I'm probably going to do away with it once I'm pretty sure the Atom file works.
Thursday, February 19, 2004
Random hacks: RSS1, not RSS2
I've been having trouble getting various kinds of URLs to work in my RSS feed. On advice from Marco d'Itri, I've switched from RSS2 to RSS1 and will try Atom later.
Tuesday, February 17, 2004
Random hacks: IE and Opera don't like '
I changed my log generating program from using
" to using ' to
fix a bug. This was nice, and the page even validated. Today
people with IE or Opera started telling me that their browsers
don't understand that named entity, so I have changed it to
use ' instead.
Random hacks: comments@liw.iki.fi re-enabled
Due to a comment by Daniel Silverstone, I have re-enabled the
comments@liw.iki.fi mailing list. It is still
moderated to avoid spam.
Random hacks: figlet saves the day
The embedded software I write at work logs to a serial port. When the platform software (i.e., Hedgehog) starts, it prints out a number of lines that report hardware capabilities and such, which is useful for debugging. After the application software (the one written in Lisp) starts running, it writes its own debugging log lines. To make it easier to notice when the application starts running, and which application, I now use figlet to create a few lines of ASCII graphics to make a logo of sorts:
__ __
| \/ |_ _ __ _ _ __ _ __
| |\/| | || | / _` | '_ \ '_ \
|_| |_|\_, | \__,_| .__/ .__/
|__/ |_| |_|This is the kind of thing that makes a programmer's life worthwhile, of course. Forget about implementing your own programming languages, ASCII graphics is the True Way!
Friday, February 13, 2004
Random hacks: I'm still stupid
I wrote a small Python program to convert the master
XML file for this log into XHTML and RSS. A part of that
code is a function to escape certain characters using
HTML entities. One of the characters to be escaped is
the apostrophe ('). My code converted it to
" and this made me happy, until it was
pointed out to me today that it is quite wrong. I fixed it
to use ' instead.
So here's a test of the problem entities: the entity
& should give the ampersand character
(&), < should give less
than (<), > should give
greater than (>), ' and
' should give an apostrophe ('),
and " and " should give
double quotes (").
There. I think these now work for both XHTML and RSS output. If not, I'm sure I'll get to hear about it.
Sunday, February 01, 2004
Random hacks: URLs in my RSS should work now
Scott James Remnant pointed out to me that
' doesn't seem to work in the code that
runs Planet Debian.
This made the URLs in my RSS feed not
work. I've changed into using "
instead, as this should work better.
Thursday, January 29, 2004
Random hacks: Generating Finnish SSNs
Some time ago a friend was testing a database that included, among other things, Finnish social security numbers, and needed something to test it with. Instead of having to generate syntactically valid numbers by hand, I wrote a ten line Python script to do that. Might as well put it on the web, in case someone else needs it.
Tuesday, January 20, 2004
Random hacks: RSS
Well, someone requested that I add RSS, so I did it. According to feedvalidator.org the file I generate is valid, but since I don't use RSS myself, I don't know if it actually works in any useful way. Please tell me.
Monday, January 19, 2004
Random hacks: Log re-engineering
I decided that I wanted to provide permanent links to log entries and to implement this I had to abandon my old way of making the log. I started writing the log as a plain HTML file, at the end of May, and have only added a small script to create per-category page. For permanent links, I would have had to do unpleasantly much manual editing, so I decided it was time to do something fancier.
I don't want to run a "blog engine" on liw.iki.fi, for various reasons. I may some day write a log entry to explain this. For now, take it for given that I want to have the log as static HTML files.
After experimenting with a few things, I ended up converting the old log entries into one large XML file, from the the HTML files are generated. I made a quick prototype for the HTML generation with XSLT, but as usual, the expressive power of XSLT failed as soon as I wanted to do something non-simple. It's not that XSLT couldn't be made to do them, it's that it becomes a headache to do them. Instead, I wrote a 531 line Python program to read in the XML file and generate the various HTML files. You can see the result now.
Apart from minor changes in the visual design of the log, the new thing is a "Permanent link" link at the end of each entry. So, in the future, if you want to refer to a particular entry, use that link.
The front page will contain a couple of days' worth of entries.
Eventually there might be an RSS feed as well, if anyone shows any interest in such.